


AI-powered synthetic data is gaining attention due to its ability to simulate people's behaviour and preferences at a lower price. According to a recent survey, 81% of marketers said they use or intend to use generative AI to generate synthetic data. Synthetic data forms the basis for creating 'synthetic users' that model how your actual users could respond or interact. These methods can be handy for rapid testing, pattern recognition, and generating hypotheses when time, budget, or user access is limited.
As this topic gains traction, it's helpful to ask: What are we learning from synthetic data? How reliable are synthetic users' answers? And can they ever replace talking to real people?
In user research, we aim to understand why and how people make sense of their context, which they continuously co-construct while it simultaneously shapes their behaviour, expectations, and decisions. Each of our methods, from lab experiments to ethnographic fieldwork, uncovers different insights and has its limitations. With this in mind, our team has recently compared synthetic and real respondents during research activity, reviewed emerging studies and the latest tools, and examined what synthetic users can and cannot tell us.
How Synthetic Users Are Created
Synthetic users are built by AI models trained on existing data. Some rely on statistically likely patterns to generate "typical responses"; others use large language models (LLMs) trained on vast datasets. In practice, these two approaches are often combined. The process begins with data based on observed human behaviour, which is recorded, cleaned, and usually interpreted before being fed into the model. The theory is that LLMs encode general behavior patterns, with the proper prompts and data inputs, and can mimic how real people might respond.
Companies enrich AI with their internal data, like customer records or past research logs, to make these simulations better reflect a particular audience. However, insights from synthetic data are shaped by the training data, not by observing live events in real-time, treading a fine line between simulating and discovering new insights.
The Reality Check on Validation
Validating synthetic users against real behaviour remains challenging. Minor changes to how they are built or trained can produce different results. There are no clear industry standards for testing the quality of the models, and little transparency regarding how commercial versions are developed.
A 2023 analysis by researchers at Columbia and Stanford found that OpenAI models tend to exhibit liberal, educated viewpoints, which are likely influenced by the training data and human feedback used to fine-tune them. Another study by James Bisbee in 2024 showed that synthetic users tend to exhibit less variety. They can be susceptible to the wording of questions (prompts) and may not remain consistent over time. Similarly, our recent side-by-side comparisons revealed significant differences between commercially available synthetic users and real users, particularly in response to experience-based or category-choice questions. They tended to mimic simple rating-scale answers more closely.
A 2023 study from Stanford and DeepMind trained AI 'digital twins' on 1,000 in-depth interview transcripts to "develop" their personalities. When tested using well-established psychological surveys such as the Big Five, the digital twins' responses matched those of their human counterparts 85% of the time, outperforming simpler persona or demographic-based models.
Rather than true "thinking", the twins relied on pattern recognition, drawing on well-known correlations in Big Five personality psychology and interview cues. While they performed well on standardised, research-backed assessments, they struggled to generalise beyond them (e.g., predicting behaviour in strategic games). Yet this is precisely what strategic product and service design demands: insight into shifting realities that rarely fit standardised frameworks.
Understand the Trade-Offs
Bias in, bias out
A primary concern is that synthetic users are trained on existing data. If that data is skewed or incomplete, synthetic models risk recycling and amplifying it.
Missing Outliers
Synthetic users reflect statistically likely "average" behaviour. However, in user research, breakthroughs often come from understanding the outliers—users with uncommon needs or edge-case frustrations that expose hidden issues.
Think of Netflix: Their game-changing decision to drop late fees (and eventually pivot to streaming) was sparked by listening to a handful of frustrated users, not a broad trend. Synthetic users often miss these margins where innovation might thrive.
Plausible Answers, False Assumptions
Suppose a factor relevant to your research was not included in the AI’s training data, whether because it was overlooked, unmeasured, or not yet recognised. In that case, it will remain invisible to a synthetic user. They cannot anticipate behaviour in new contexts or identify emerging needs. The catch? They may still produce plausible answers but lead to misguided design decisions.
In a simulated pricing test, real users reacted directly to a price. By contrast, a synthetic user inferred meaning (e.g., a higher price equals better quality) because this association appeared in its training data. Even if a key variable isn’t present, they may still generate confident responses; if a pattern is typical, they might wrongly apply it to new situations.
No Contradiction and Emotional Depth
Synthetic users lack connection to the broader social and cultural context real people shape and are shaped by, a relational dynamic inaccessible to models trained solely on data. Humans change their minds, contradict themselves, and find it hard to explain why. Synthetic users don’t experience emotion, hesitation, or cognitive load, nor can they reflect tonal shifts. While this 'smoothness' and ‘sycophantic’ responses lacking critical nuance may seem appealing, contradictions often provide the most valuable insights. Unlike humans, they don't have lived experiences such as tensing up when an interface recalls a past mistake. In our comparative study, participants linked voice interface frustrations to past failures, a link absent in synthetic responses.
The Validation Gap
When a synthetic user supports your assumptions, how do you validate them? In user research, we triangulate findings using diverse methods and follow-up questions. We are looking for gaps between what people say and what they do, as behaviour often diverges from self-reported intentions and values. You get a narrative with synthetic users, but there's no actual behaviour to observe, limiting your ability to verify the "insight."
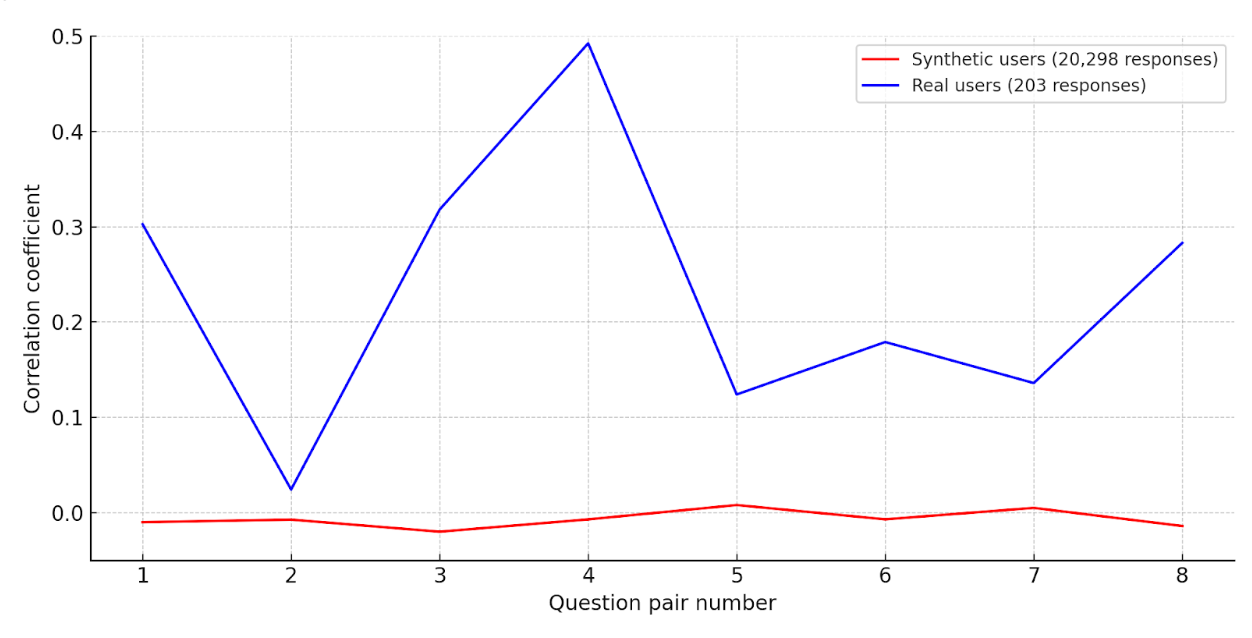
Missing the bigger picture: why relationships are key
Our study explored whether real-world habits (like using meditation or language apps outside cars) would translate into interest in new settings, precisely, in-car functionalities.
Real users revealed strong connections: established habits and recent relevant experiences in cars (like needing urgent information) boosted interest in related new car functionalities. However, not all strong habits carry over to a car—context matters—and understanding this nuance helps to pinpoint what will and won't work.
Synthetic users showed none of these patterns. Their answers lacked internal coherence—correlations were flat or missing as if different people answered each question (Figure 1).
Without these relational links, it's hard to answer key strategic questions like "Who is this for?" or "What drives their interest?" While simulations might mirror general trends, they miss the coherence crucial for segmentation and targeting. Habits, expectations, and context and their interconnections shape actual user behavior—connections that synthetic data can't yet replicate.
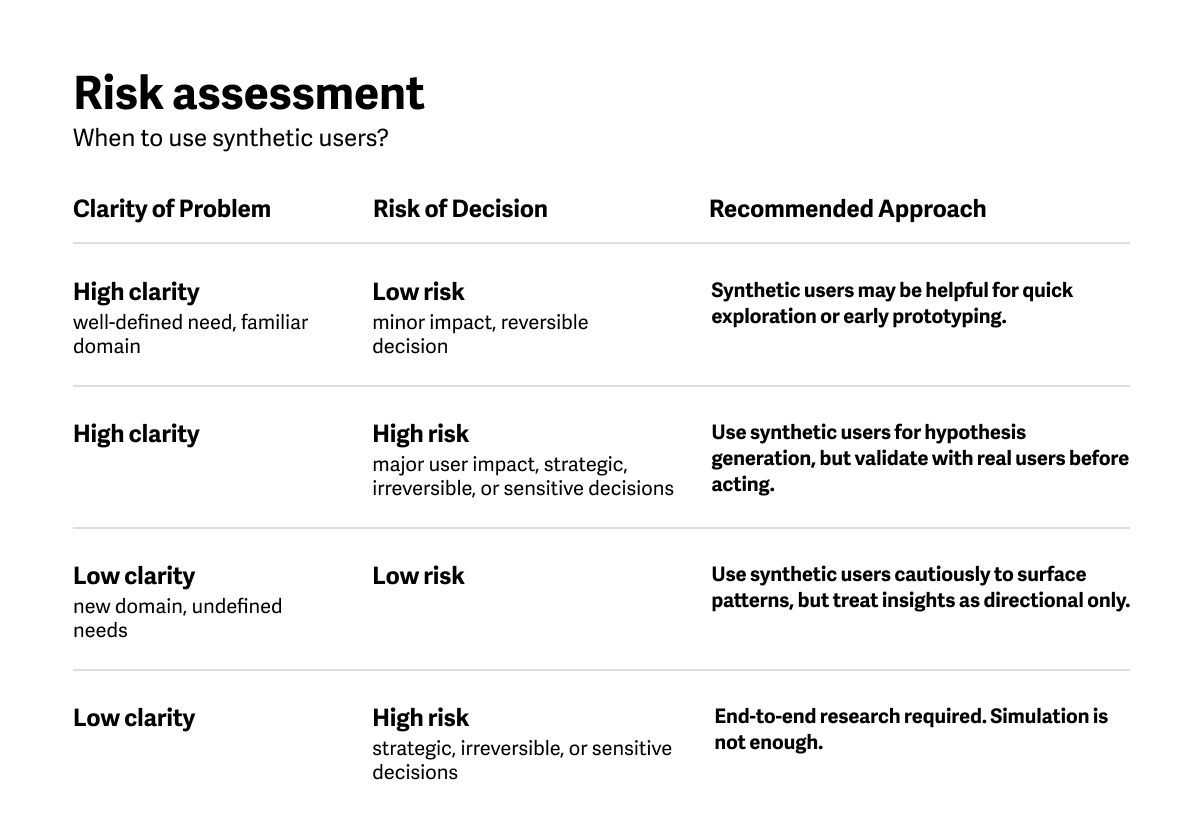
How to Use Synthetic Users
Don't replace—augment. Use synthetic users to complement research. Use them to generate initial hypotheses and prepare more effectively for fieldwork and studies with actual end users.
Beware of the efficiency illusion. Creating a reliable synthetic user set still requires a solid base of actual user data. Use triangulation to identify contradictions, gaps, and creative workarounds that synthetic insights will likely miss. Consider the efficiencies you are gaining and where you are adding necessary (or extra) steps.
Beware of black-box solutions. Ask how and by whom the synthetic users were generated, what datasets the model was trained on, the modeling techniques used, and the tool’s capabilities and limitations. Assess credibility by examining its validation processes and any third-party peer reviews.
Conclusion
While synthetic users offer speed and scalability, they are not yet capable of fully replicating the complexity of human behavior, including emotional and strategic responses shaped by evolving context.
Synthetic user platforms show promise for early-stage tasks such as exploring trends or generating hypotheses, but their value depends on the quality of real-world data. Many of these platforms are still in the experimental stage. As researchers, we assess where and when they can be integrated into our research toolkit. Considering business goals and risks, we evaluate what they can deliver — and, equally importantly, what they cannot.
Without validation and scrutiny, synthetic users may overlook game-changing insights, leading to costly strategic missteps. In high-stakes situations like new domains, critical user flows, or early-stage innovation, insights based on real human experience remain invaluable.
Need help setting up your research activities? Feel free to reach out.
Go further: Download our synthetic data research checklist
This checklist guides the critical evaluation of models that simulate user behavior or generate insights. It emphasizes the importance of high-quality, inclusive data, sound modeling, internal consistency and transparency.
