


Syntetické dáta generované pomocou AI si získavajú čoraz väčšiu pozornosť vďaka schopnosti simulovať ľudské správanie a preferencie rýchlo a lacno. Podľa nedávneho prieskumu, až 81 % marketérov používa alebo plánuje využívať AI na generovanie synte-tických dát. Tie sú základom pre tvorbu "syntetických používateľov" – modelujúcich, ako by skutoční používatelia mohli reagovať či interagovať. Keď máte nedostatok času, financií alebo respondentov, môžu vám pomôcť pri rýchlom testovaní, identifikácii vzorcov správania či formulovaní hypotéz.
S rastúcou popularitou je dôležité pýtať sa: "Čo dokážeme zistiť zo syntetických dát? Nakoľko sú odpovede syntetických používateľov spoľahlivé? A nahradia raz úplne výskum s reálnymi ľuďmi?"
Pri používateľskom výskume sa snažíme pochopiť, prečo a ako ľudia vnímajú svoj kontext, ktorý spoluvytvárajú a ktorý ich formuje. Každá naša metóda – od laboratórnych experimentov po etnografický terénny výskum – odhaľuje iné poznatky a má svoje obmedzenia, rovnako tak aj syntetický výskum. Preto sme chceli pochopiť, čo nám syntetickí používatelia môžu ponúknuť v porovnaní so skutočnými respondentmi a kde sú ich hranice.
Ako vznikajú syntetickí používatelia
Syntetickí používatelia sú tvorení pomocou AI, modelmi trénovanými na existujúcich dátach. Niektoré sa spoliehajú na štatisticky pravdepodobnostné vzorce, aby generovali "typické odpovede", iné využívajú veľké jazykové modely (LLM), trénované na rozsiahlych datasetoch. V praxi sa tieto prístupy často kombinujú. Proces začína údajmi z pozorovania ľudského správania, ktoré sa ešte pred vložením do modelu často čistia a často aj interpretujú. Základná myšlienka spočíva v tom, že LLM dokáže zakódovať všeobecné vzorce správania a pri správnych podnetoch a vstupných údajoch napodobniť reakcie skutočných ľudí.
Firmy často využívajú informácie o zákazníkoch, dáta z minulých výskumov a ďalšie interné zdroje na trénovanie modelov, aby simulácie odrážali ich cieľovky. Zistenia zo syntetických údajov sa však formujú na základe tréningových dát, nie na základe pozorovaní udalostí v reálnom čase. Hranica medzi simuláciou a skutočným objavovaním nových poznatkov je tak veľmi tenká.
Vieme tieto dáta validovať?
Spoľahlivosť syntetických používateľov sa stále ťažko overuje. Už malé zmeny pri tvorbe či trénovaní vedú k rozdielnym výsledkom. Chýbajú jasné štandardy testovania kvality modelov a vývoj komerčných riešení je často netransparentný.
Analýza výskumníkov z Kolumbijskej univerzity a Stanfordu z roku 2023 ukázala, že modely OpenAI odzrkadľujú hodnoty liberálnych a vzdelaných vrstiev spoločnosti. Tieto sklony pravdepodobne vyplývajú z charakteru tréningových dát a ľudskej spätnej väzby použitej pri ich dolaďovaní. Štúdia Jamesa Bisbeeho z roku 2024odhalila, že syntetickí používatelia sú menej rozmanití, citlivejší na znenie otázok a časom nekonzistentní. Naše nedávne porovnania tiež odhalili veľké rozdiely medzi komerčnými syntetickými a skutočnými používateľmi, najmä pri otázkach založených na skúsenostiach či kategorických otázkach. Syntetickí používatelia lepšie napodobňovali odpovede na hodnotiacich škálach.
Výskumníci zo Stanfordu a DeepMind v roku 2023 vytrénovali "digitálne dvojičky" na základe 1 000 prepisov hĺbkových rozhovorov s reálnymi respondentmi, aby simulovali ich osobnosť. Pri testovaní osvedčenými psychologickými dotazníkmi, ako je Big Five, sa odpovede digitálnych ľudských dvojníkov zhodovali v 85 % prípadov. Prekonali tak jednoduchšie modely založené na demografických ukazovateľoch a persónach.
Dvojičky sa však namiesto skutočného "premýšľania či rozhodovania" spoliehali na rozpoznávanie vzorcov. Ich silnou stránkou boli bohaté kvalitatívne rozhovory (základ simulácie) a štandardizované dotazníky so známymi väzbami na ďalšie črty. Mimo tohto rámca však boli výsledky menej presné, napríklad pri predpovedaní správania v strategických hrách. Práve takéto správanie je pritom základom strategického dizajnu produktov a služieb: porozumieť meniacej sa realite, ktorá zriedka zapadá do pevných či štandardizovaných rámcov.
Úskalia syntetických dát
Skreslené vstupné dáta
Syntetickí používatelia sa trénujú na existujúcich dátach, čo je jedno z najväčších rizík. Ak sú dáta skreslené alebo neúplné, syntetické modely môžu tieto chyby recyklovať, alebo dokonca znásobovať.
Absencia krajných hodnôt (tzv. outliers)
Syntetickí používatelia odrážajú štatisticky pravdepodobnostné, "priemerné" správanie. Vo výskume s používateľmi však inovácie často vznikájú na základe pochopenia používateľov s neobvyklými potrebami či frustráciami, ktoré odhaľujú skryté problémy.
Dobrým príkladom je Netflix. Jeho rozhodnutie zrušiť poplatky za oneskorené vrátenie a napokon prejsť na streamovanie nevzišlo zo širokého trendu, ale zo sťažností malej skupiny frustrovaných používateľov. Práve okrajové prípady často vytvárajú priestor pre inovácie – tie však syntetickí používatelia spravidla nedokážu zachytiť.
Vierohodné odpovede a chybné predpoklady
Ak v tréningových dátach chýba kľúčový faktor (pretože nebol meraný alebo rozpoznaný), model ho nezachytí. Nedokáže tak predvídať správanie v nových kontextoch ani identifikovať vznikajúce potreby. Napriek tomu môže produkovať vierohodne znejúce odpovede, ktoré môžu viesť k chybným dizajnovým rozhodnutiam.
Napríklad pri simulovanom teste cien reagovali skutoční používatelia priamo na cenu. Syntetický používateľ však odôvodnil, že vyššia cena znamená lepšiu kvalitu, lebo táto asociácia bola v jeho tréningových dátach. Aj keď kľúčová premenná chýba, syntetickí používatelia môžu generovať zdanlivo validné odpovede; ak je vzor typický, môžu ho nesprávne aplikovať na nové situácie.
Chýbajúci rozpor a emocionálna hĺbka
Ľudia menia názory a často si protirečia bez toho, aby to vedeli vysvetliť. Syntetickí používatelia to nerobia, no práve tieto rozpory nám vo výskume často poskytujú najcennejšie poznatky. Syntetickým používateľom chýba aj prepojenie na širší spoločenský a kultúrny kontext, ktorý ľudia spoluvytvárajú a ktorý ich zároveň formuje. Nezažívajú emócie, váhavosť, kognitívnu záťaž ani nereflektujú intonačné zmeny. Nenesú si osobné spomienky, napríklad moment, keď sa respondent cíti neisto, lebo mu používateľské rozhranie pripomenie predchádzajúce chyby.
AI často poskytuje príliš súhlasné odpovede (sycophantic) ktorým chýba kritická nuansa a teda aj hĺbka potrebná na predvídanie správania v reálnom svete. V našej komparatívnej štúdii reálni používatelia otvorene vyjadrovali frustráciu z predchádzajúcej negatívnej skúsenosti s hlasovým ovládaním a obavy o jeho kvalitu. Takáto spätná väzba, zakorenená v pamäti a skúsenosti a formujúca interakciu s dizajnom v syntetických odpovediach úplne chýbala.
Problém s validáciou
Ak syntetický používateľ podporí naše predpoklady, ako ich overíme? Pri výskume používateľov stále triangulujeme zistenia rôznymi metódami a doplňujúcimi otázkami. Hľadáme rozpory medzi tým, čo ľudia hovoria, a tým, čo robia, keďže správanie sa často líši od ich deklarovaných zámerov a hodnôt. Od syntetických používateľov získavame naratív, no nemôžeme pozorovať ich správanie, čo obmedzuje našu schopnosť dáta overiť.

Chýbajúci širší obraz: prečo sú vzťahy kľúčové
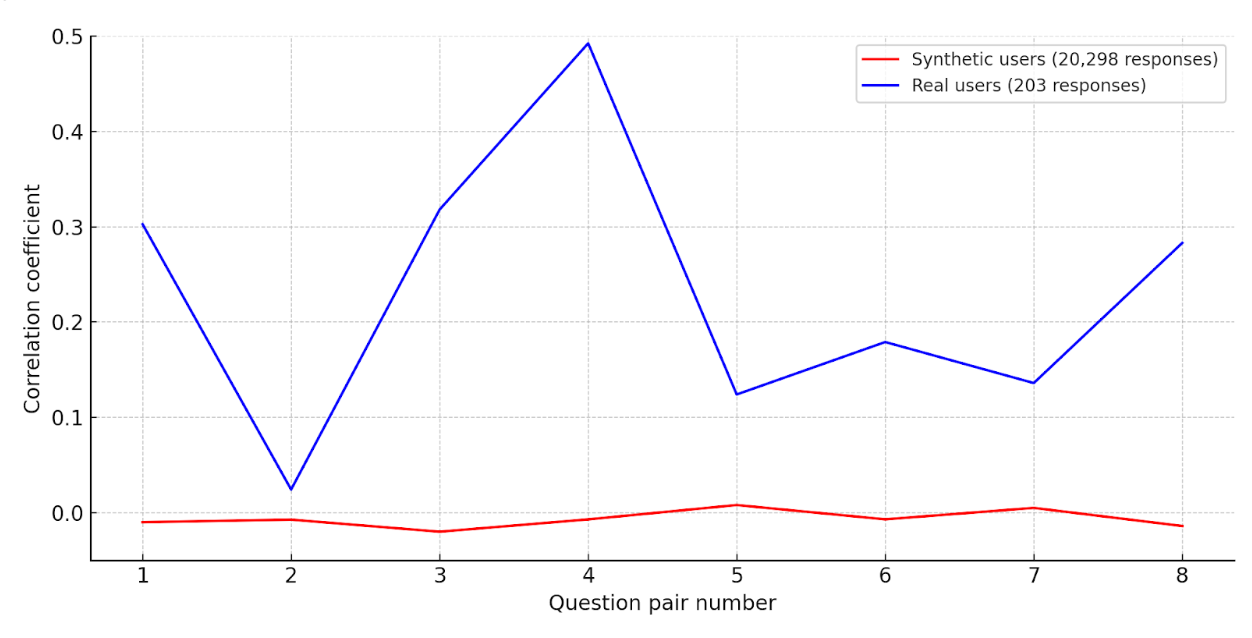
V našej štúdii sme skúmali, či sa vzorce správania (napr. používanie meditačných aplikácií alebo aplikácií na učenie jazykov) premietnu do záujmu o nové, súvisiace služby – konkrétne o funkcie v aute.
Reálni používatelia vykazovali silné vzťahy medzi odpoveďami: čím silnejšie boli zaužívané zvyky a relevantné skúsenosti (napr. potreba urgentných informácií o vozidle), tým vyšší bol záujem o súvisiace funkcie v aute. Nie všetky silné návyky sa však preniesli do kontextu vozidla a pochopenie tejto nuansy pomohlo predpovedať, čo bude fungovať a čo nie.
Syntetickí používatelia nevykazovali žiadne súvislosti. Ich odpovediam chýbala vnútorná konzistentnosť – korelácie medzi otázkami boli slabé alebo chýbali, akoby na každú otázku odpovedal iný človek. (Graf 1.)
Bez týchto vzťahov je ťažké odpovedať na kľúčové strategické otázky ako: "Pre koho je to určené?", "Čo poháňa ich záujem?" alebo "Aké sú ich motivácie?". Simulácie môžu odrážať všeobecné trendy, no chýba im konzistentnosť dôležitá pre segmentáciu a definovanie cieľových skupín. Zvyky, očakávania, kontext a ich vzájomné prepojenia formujú správanie používateľov – súvislosti, ktoré syntetické dáta zatiaľ nedokážu verne replikovať.
Ako používať syntetických používateľov
Nenahrádzajte – dopĺňajte. Syntetických používateľov používajte ako doplnok výskumu, napríklad na tvorbu počiatočných hypotéz a prípravu štúdií so skutočnými koncovými používateľmi.
Ilúzia efektivity. Spoľahlivý syntetický súbor používateľov si vyžaduje pevný základ dát od skutočných používateľov. Trianguláciou identifikujte rozpory a medzery, ktoré syntetické dáta pravdepodobne prehliadnu. Zvážte, akú efektivitu naozaj získavate a či nepridávate zbytočné kroky.
Overujte zdroje a metódy. Pýtajte sa, ako a kým boli syntetickí používatelia vytvorení, na akých dátach bol model trénovaný, aké techniky modelovania sa použili a aké sú možnosti a obmedzenia nástroja. Dôveryhodnosť kriticky posúďte preskúmaním validačných procesov a prípadných nezávislých hodnotení.
Záver
Syntetickí používatelia sa čoraz častejšie ponúkajú ako rýchlejšia alternatíva k reálnym respondentom, ide však len o jednu z metód a nástrojov. Ani pokročilé simulácie nedokážu zatiaľ plne zachytiť komplexnosť ľudského správania, najmä emocionálne či strategické reakcie ovplyvnené meniacim sa kontextom.
Platformy so syntetickými dátami môžu byť užitočné pre počiatočné úlohy, ako mapovanie trendov či tvorba hypotéz. Ich hodnota však závisí od kvality reálnych dát, na ktorých sú postavené. Mnohé tieto platformy sú stále v experimentálnej fáze. Ako výskumníci musíme kriticky hodnotiť ich miesto v procese a riziká vo vzťahu k biznisovým cieľom.
Bez validácie a kontroly môžu syntetickí používatelia prehliadnuť súvislosti dôležité na trhu alebo viesť k nákladným strategickým chybám. V rizikovom kontexte – ako sú nové domény, kritické zákaznícke cesty či počiatočné fázy inovácií – zostávajú poznatky založené na ľudských skúsenostiach nenahraditeľné.
Potrebujete pomoc s nastavením výskumných aktivít? Neváhajte sa na nás obrátiť.
O krok ďalej: Stiahnite si náš checklist pre výskum so syntetickými použivateľmi
Tento checklist slúži ako návod pre kritické zhodnotenie modelov, ktoré simulujú správanie používateľov alebo generujú poznatky. Zdôrazňuje dôležitosť kvalitných a inkluzívnych dát, rizík a transparentnosti pri výskume.
